Simplifying Blog migration with Automation: Ghost to Hashnode
The journey of a tech blogger who fought his way to a better blog

Motivation
Recently I've been upset about hosted Ghost blogging platform for the following reasons:
- It was too expensive. Last year, I paid $300 for Ghost "Creator" plan just to be able to change the theme of my blog.
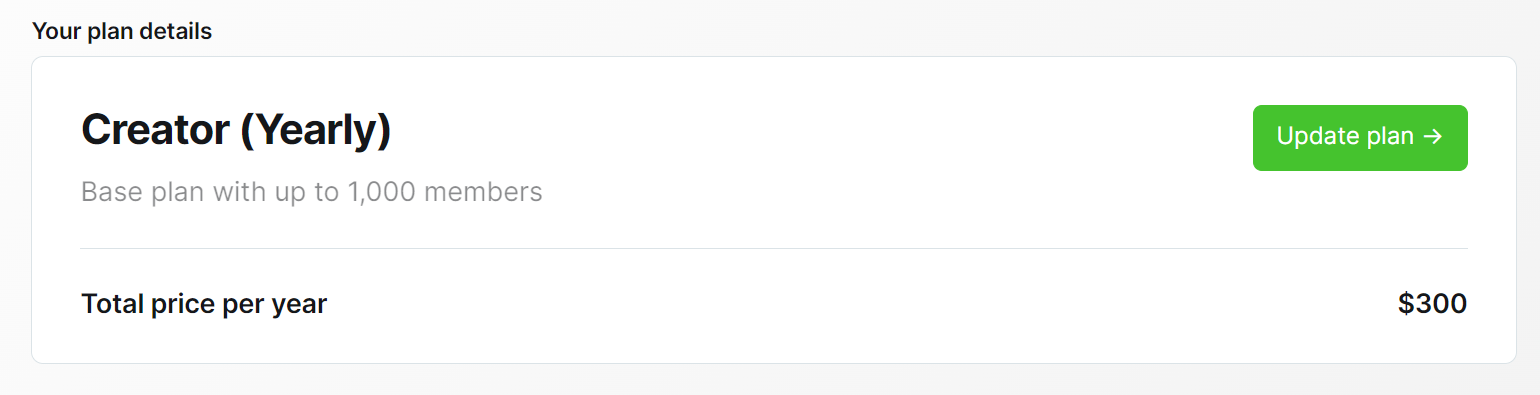
- It has no downgrade option. Once I upgraded to the Creator plan I had no option to downgrade to a lower plan. Only upgrade.

Ghost's font is not compatible with the Vietnamese language. Although I have been able to find a theme that displays fine, the editor's font still sucks. And it seems like I have no way to change it.
But the most important reason that kept me from blogging last year is that somehow Ghost is displaying WRONG images on my post. Here is the comparison of an image in the editor, and the same image in preview mode.
I even tried to publish the post to see if it was just a preview problem, but nope. Here is the image on the published post:
I always wonder why there could be such a ridiculous problem. Image displaying is a crucial function of a blogging platform. So I tried searching around for solutions and it seems this is the most related description to the problem. But yet I see no solution.
Time passed away, but until now the problem stays the same. I decided that enough is enough, and I will try to find a new platform for my blog! (Again).
Why Hashnode?
I have a tech-savvy friend who blogged a lot, one day we were sitting together at a coffee shop. In the new year atmosphere, I challenged him to blog and see who gets viral first.
But what am I missing? A proper blog 🙃. I asked him to give me some suggestions, and so he gave me Hashnode and 11ty.dev.
I looked through and thought that both looks nice. But then what caught my attention is that Hashnode was made for developers, with everything hosted and free. Cool, I can start my own blog in a matter of clicks then, and other developers will start to see my developer-oriented contents 😁. How great!
Another cool thing is that while Hashnode is a markdown blogging platform, it can automatically recognize and convert my HTML content, like this:
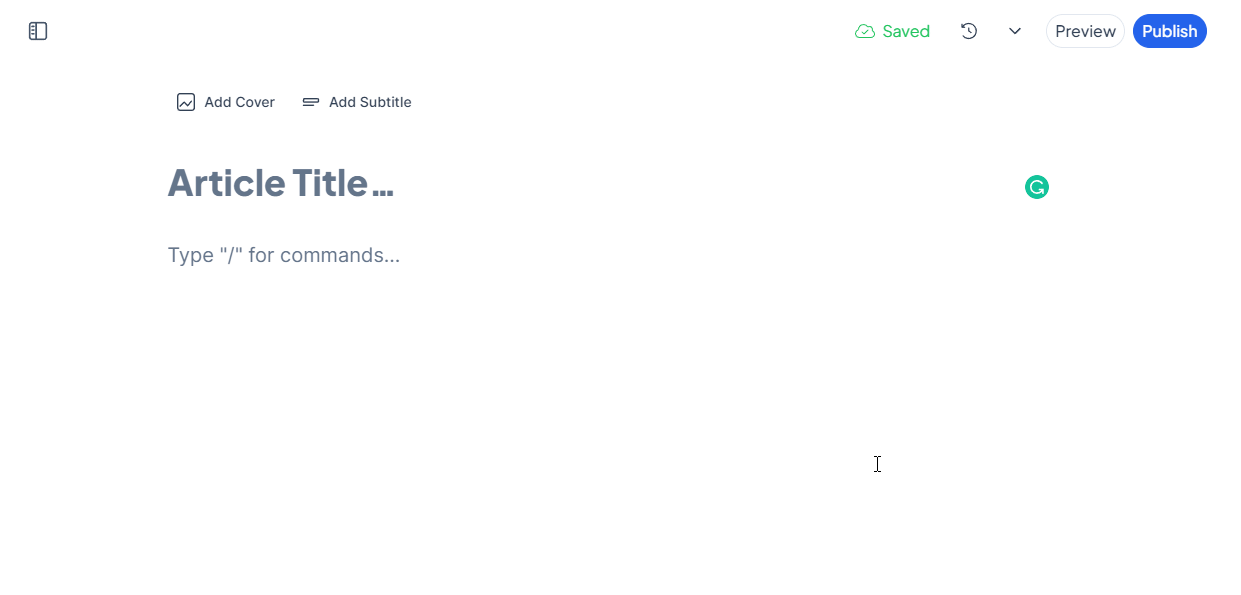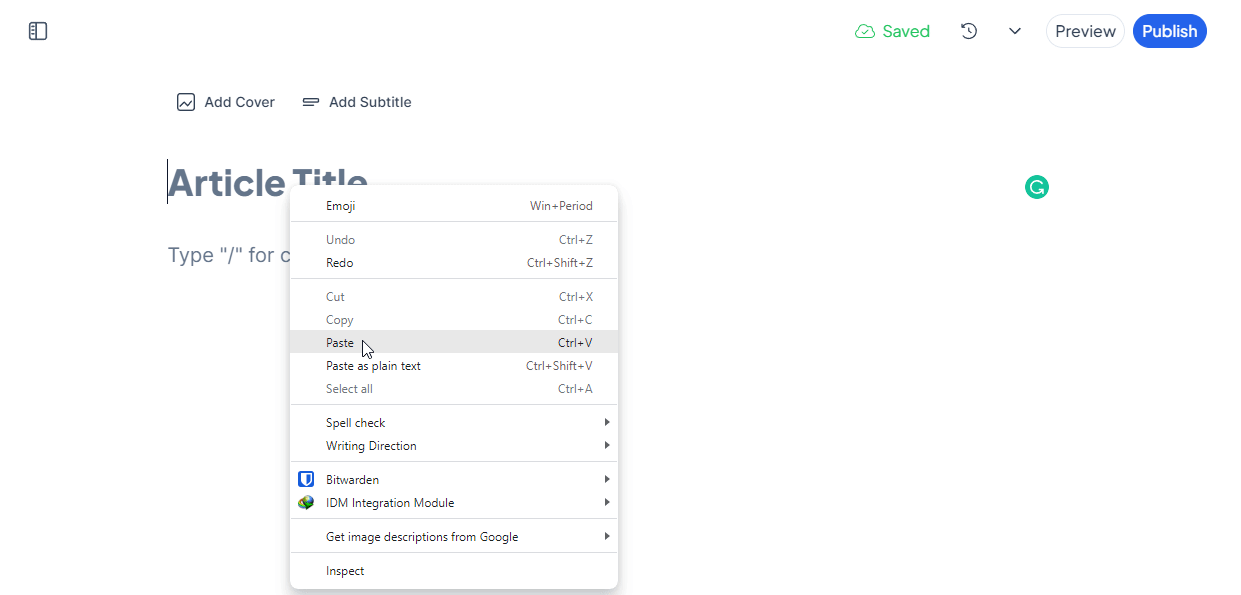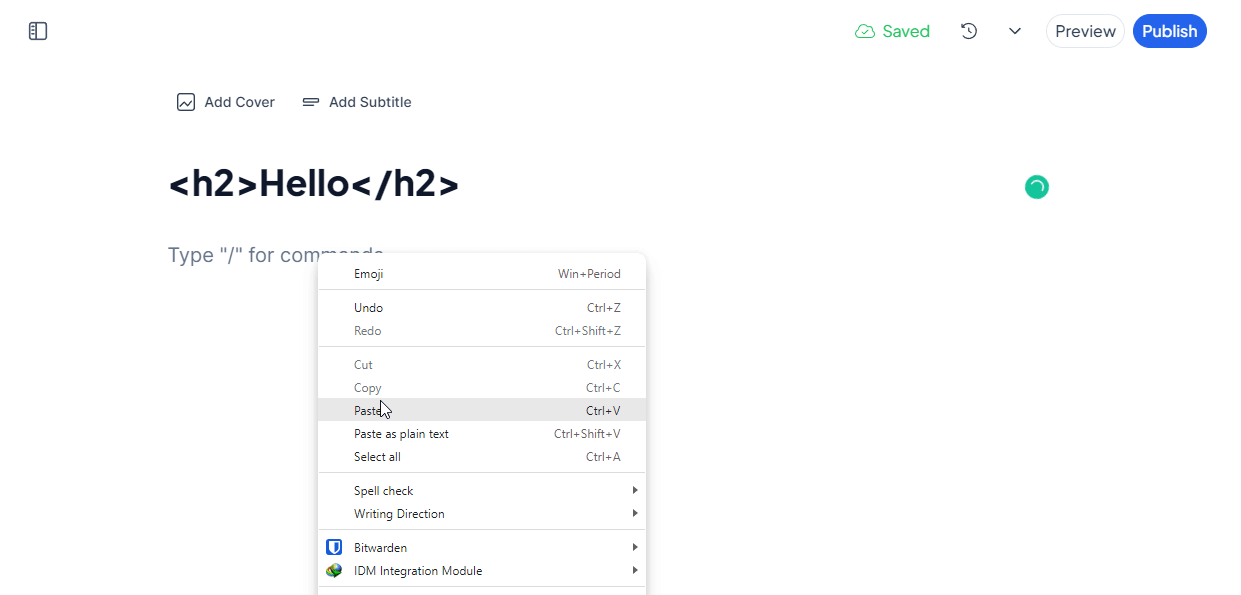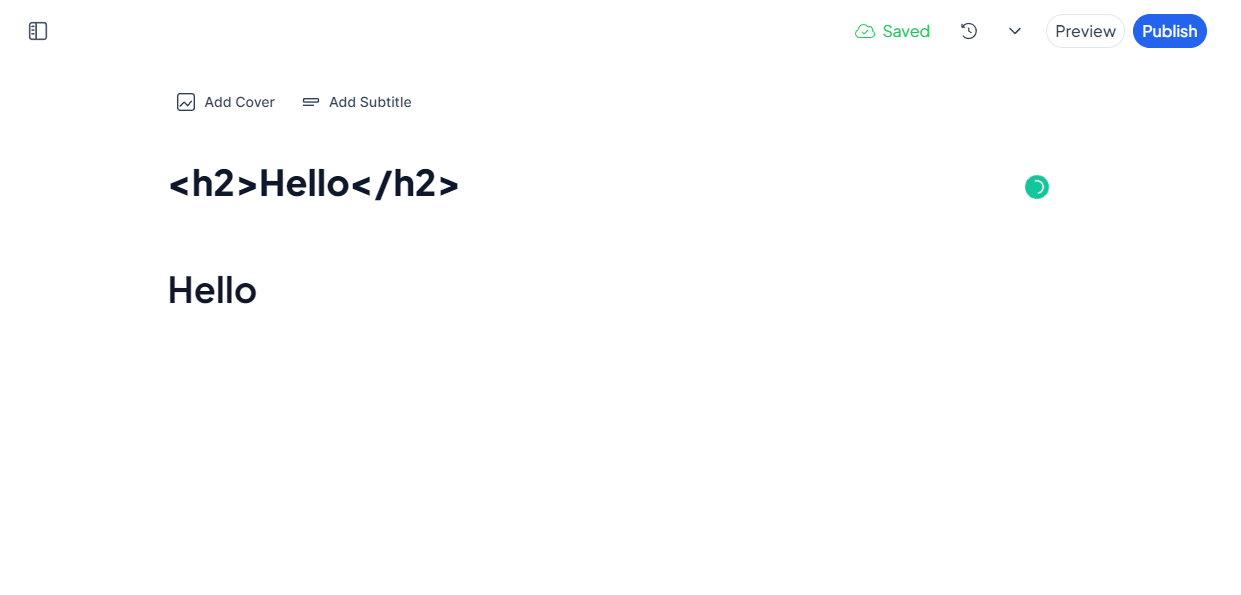
But...what are you going to do with the old blog posts?
I left them and started fresh.
Nah, just kidding. I worked so hard to create a tool to migrate all the posts, drafts, tags, and images from my old Ghost blog to my new Hashnode blog, and try to keep everything as it is. To my fellow readers, this is where the journey begins!
Initially, I looked around to see if there is any official API I could use yet and found https://api.hashnode.com/, it's a graphql endpoint and playground. but there isn't any documentation that describes it in a human manner, the docs there are just schemas, queries, and type definitions that we can refer to when making queries.
After searching around for a while I found some blog posts that teach us how to use the endpoint and construct queries the right way. I found this repo from another Vietnamese (phuctm97 - if you ever read this blog, thank you 😄).
The repo has been archived, but when I tested it still works! Using the example code below from the repo I've been able to create new posts.
import run from "./_run";
import findUser from "../find-user";
import createPublicationArticle from "../create-publication-article";
run(async () => {
const user = await findUser("trekttt");
const article = await createPublicationArticle(user.publication.id, {
title: "Article created using hashnode-sdk-js",
slug: "article-created-using-hashnode-sdk-js",
contentMarkdown:
"# [Test] Hashnode SDK JavaScript/TypeScript\n\nThis is a test article, created using hashnode-sdk-js.",
});
return article;
});
Now that we have a method to create a new post with title, slug and contentMarkdown. I went to my Ghost blog to export my blog data for testing.
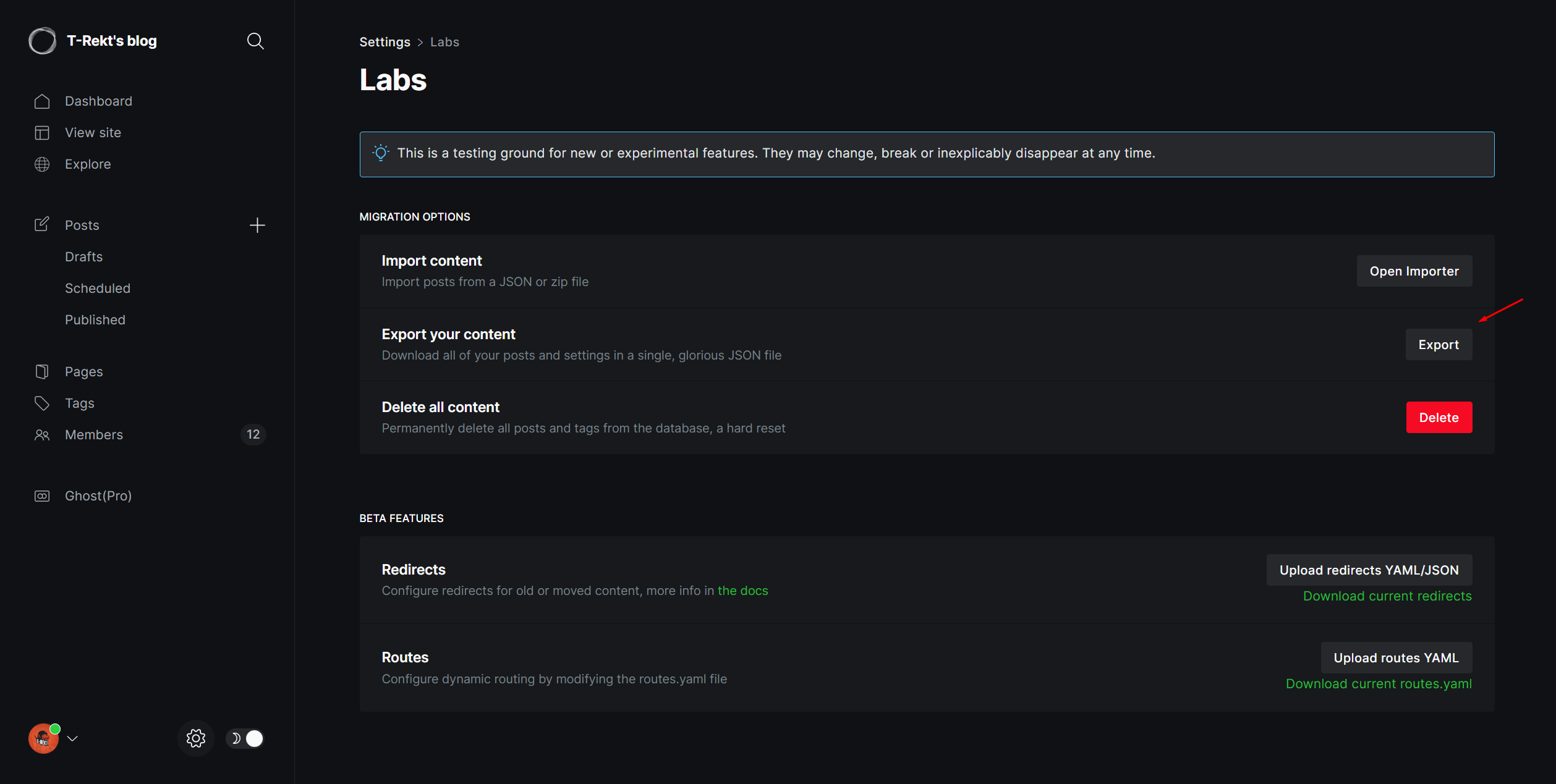
Ghost gave me the ghost-backup.json file:
With the structure like this:

And the post data structure:
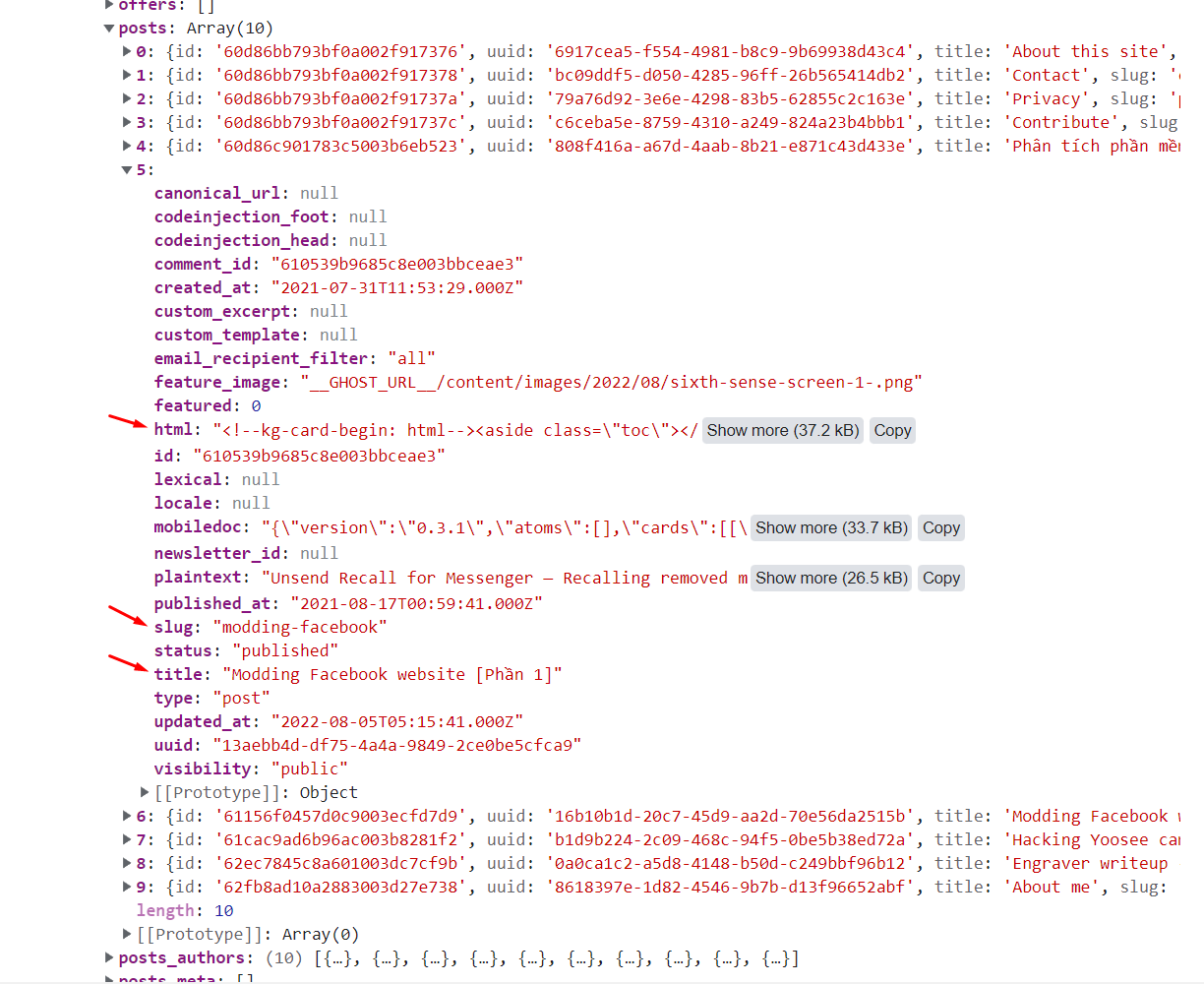
With that information in hand, I could start testing with post creation.
Testing post creation
Although I supplied post.html to the contentMarkdown field, Hashnode was able to parse it seamlessly. This is the code I used to test post creation (I already modified the source from the git repo a bit).
import dotenv from "dotenv";
dotenv.config();
import {
findUser,
createPublicationArticle,
} from "hashnode-sdk-js";
import sharp from "sharp";
const { HASHNODE_API_KEY, HASHNODE_COOKIE } = process.env;
(async () => {
const user = await findUser("trekttt");
let jsonData = JSON.parse(fs.readFileSync("./ghost-backup.json", "utf-8"));
let postsData = jsonData.db[0].data.posts;
let postsTags = jsonData.db[0].data.posts_tags;
let tags_ = jsonData.db[0].data.tags;
for (let post of postsData) {
await createPublicationArticle(HASHNODE_API_KEY || "", "<publicationId>", {
title: post.title,
slug: post.slug,
contentMarkdown: post.html
});
}
})();
Here is one of the results:
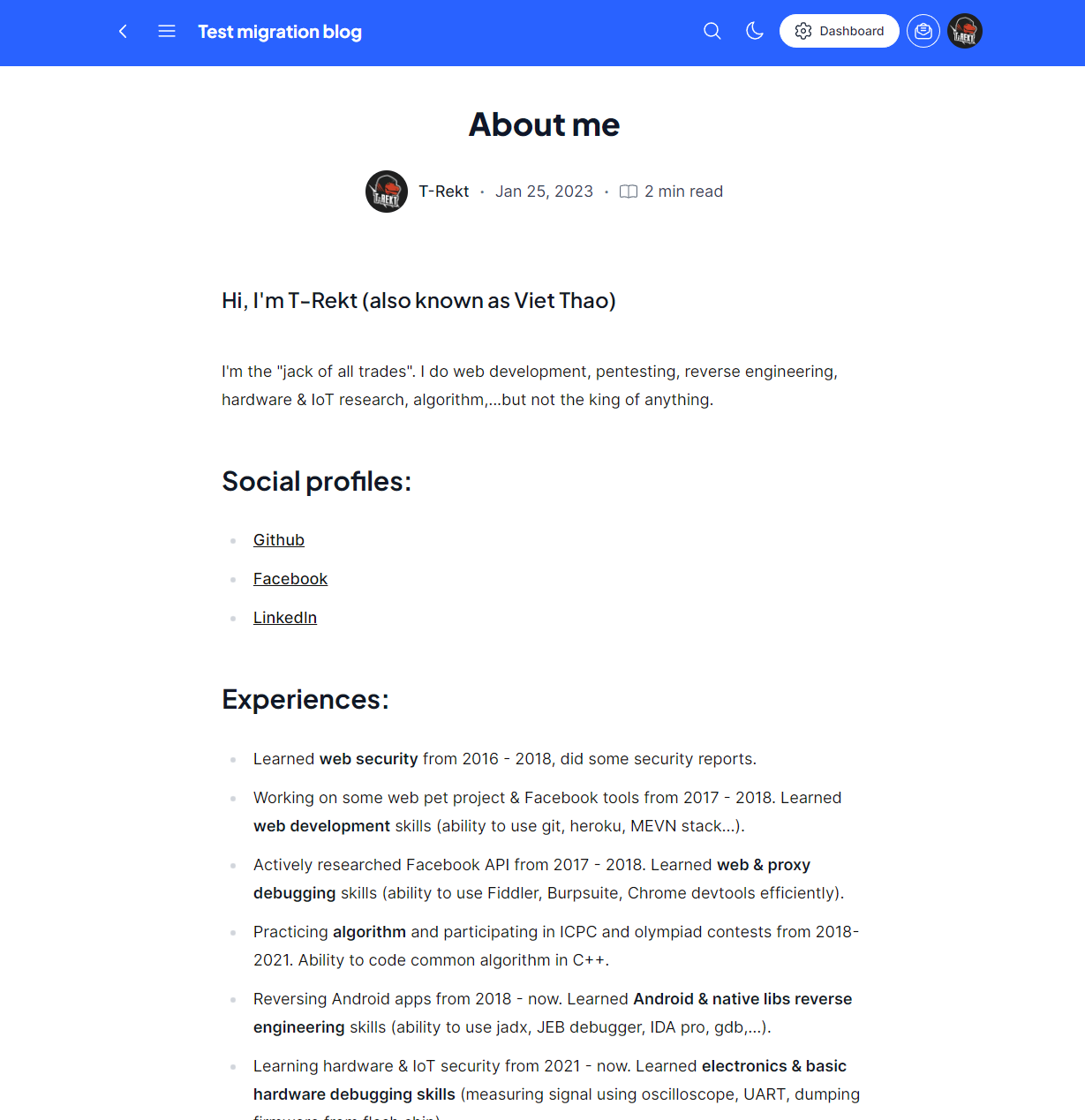
But there is one problem: All the images went missing.
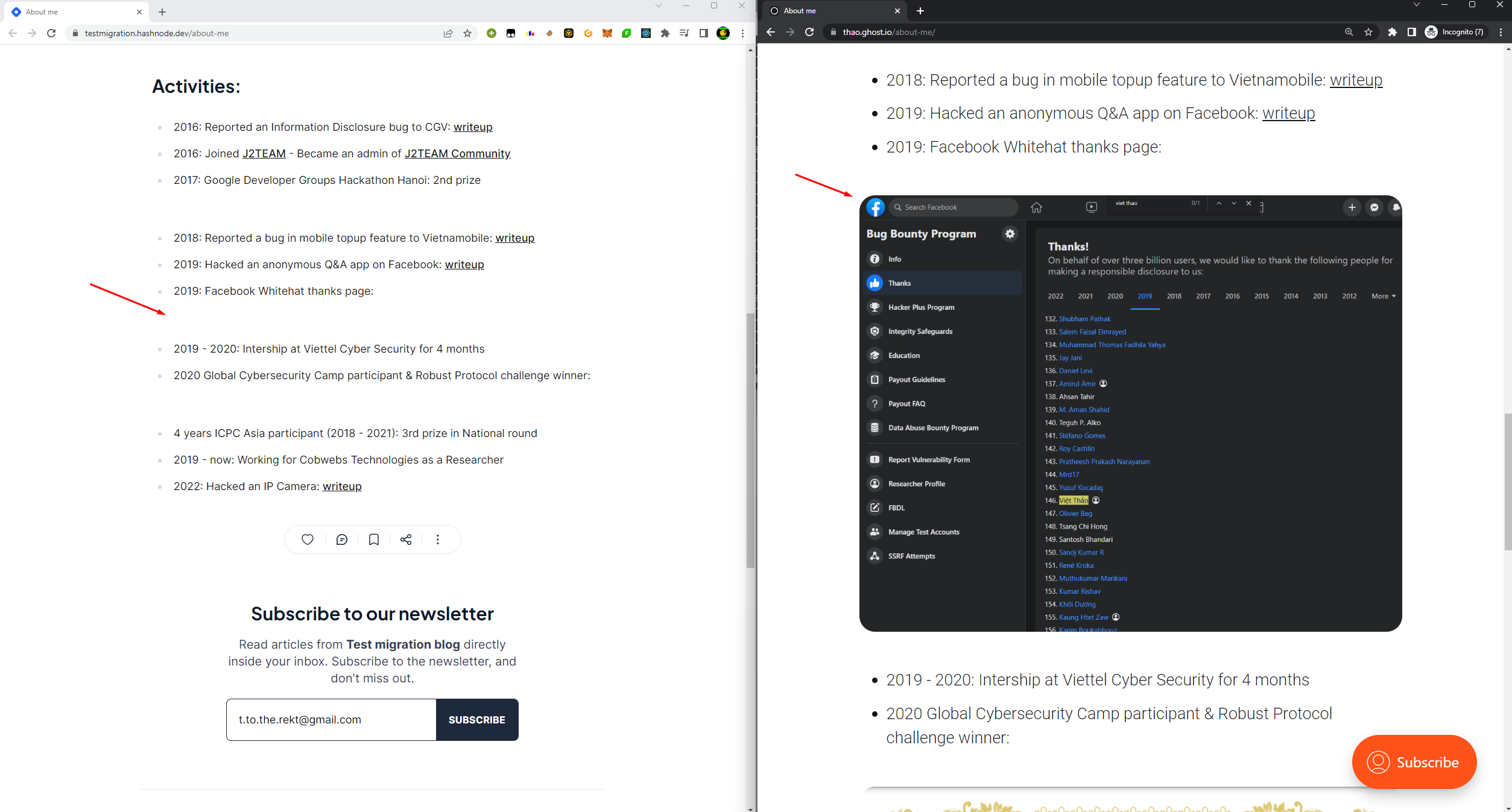
You know what? The images were not included in the backup. This seems like another way to prevent users from moving away off Ghost.
First challenge: Image backup
Look into the post's HTML content, there are references to images that were hosted on the Ghost's server:
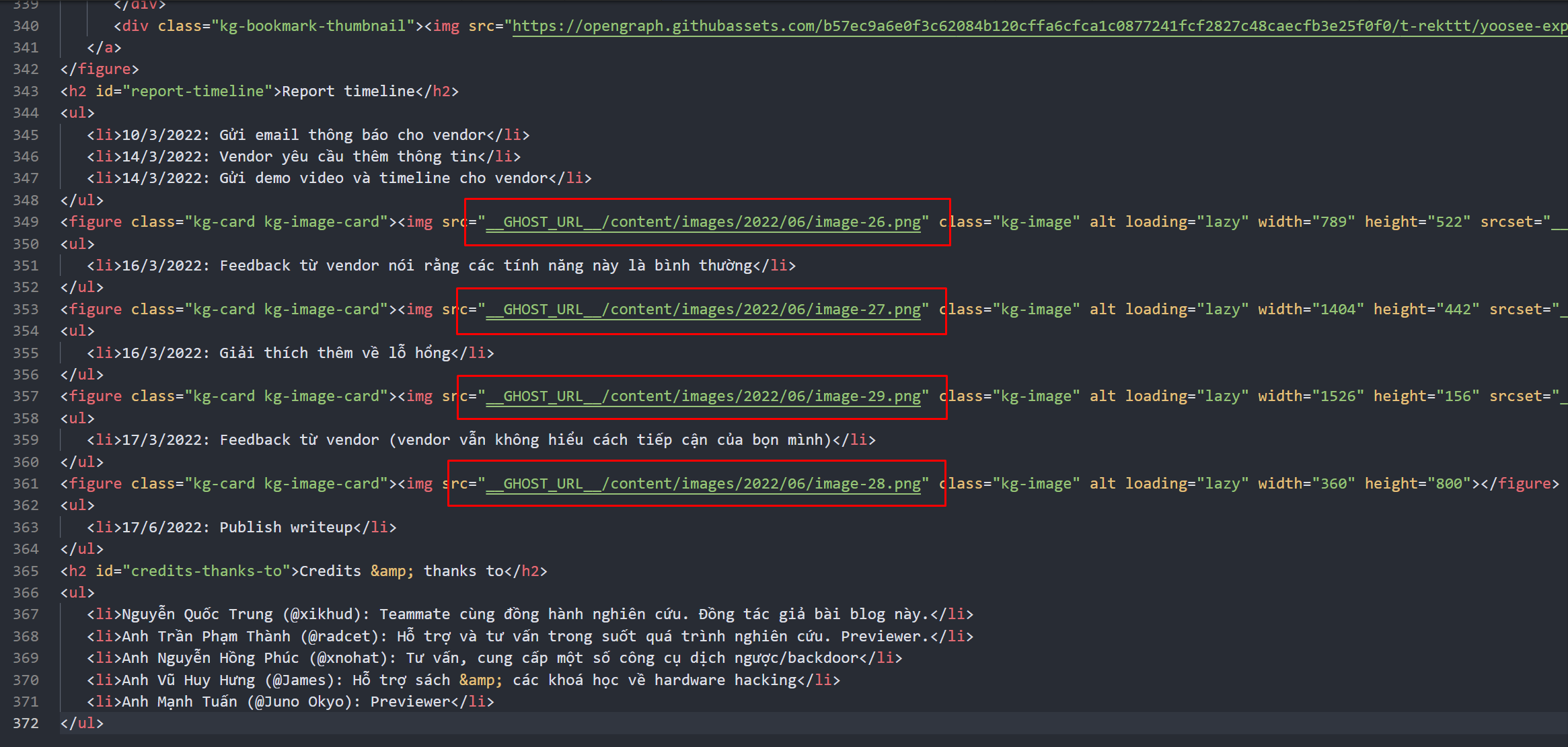
Of course I didn't want to point the images to Ghost's server because when I shut down my old blog, all of these will be gone.
This led me to writing a simple Python script that will backup the images to my local machine.
Here I used the post['mobiledoc'] field because it contains all the references to embedded items inside my post.
Images of the same post were arranged in a folder with the post['uuid'] as the name.
I also hashed the image path as md5(imagePath.encode("utf-8")).hexdigest() in order to get rid of slashes inside the filename but still allow easy mapping from the original path.
import json, requests, os
from hashlib import md5
data = open('./ghost-backup.json', encoding='utf-8').read()
jsonData = json.loads(data)
postsData = jsonData['db'][0]['data']['posts']
BLOG_URL = 'https://thao.ghost.io'
IMAGE_DIR = './images'
for post in postsData:
postId = post['uuid']
mobileDoc = json.loads(post['mobiledoc'])
cards = mobileDoc['cards']
print(postId)
for card in cards:
if card[0] == 'image':
imagePath = card[1]['src']
imageUrl = imagePath.replace('__GHOST_URL__', BLOG_URL)
print(imageUrl)
if not os.path.exists(f'{IMAGE_DIR}/{postId}'):
os.makedirs(f'{IMAGE_DIR}/{postId}')
f = open(f'{IMAGE_DIR}/{postId}/{md5(imagePath.encode("utf-8")).hexdigest()}.png', 'wb')
f.write(requests.get(imageUrl).content)
f.close()
After running the script, I have a folder structure like this:
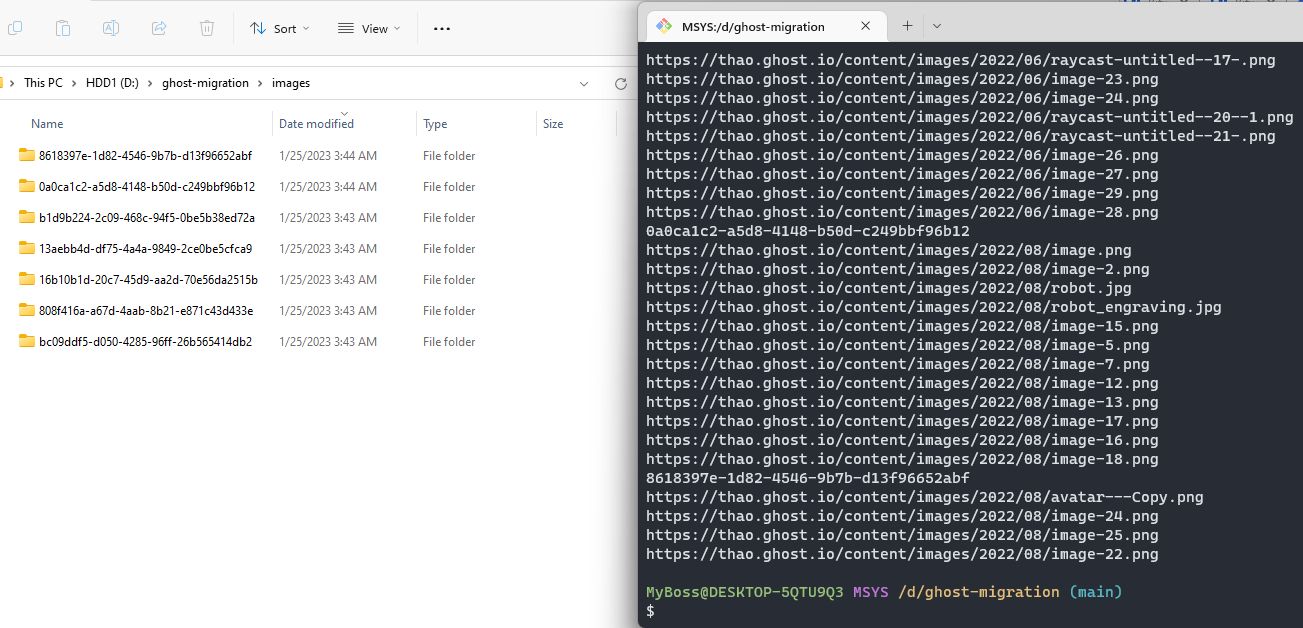
Images of a same post lying in the same folder:
Second challenge: Image restore
Now that I have all the images saved to my local machine. Next step is to upload them to the Hashnode server and replace them in my original post's content.
I create a new draft, opened the Network view on Chrome Developer Tools. Try to drag & drop an image into the editor to see what happens. Two interesting requests showed up.
Requests examination
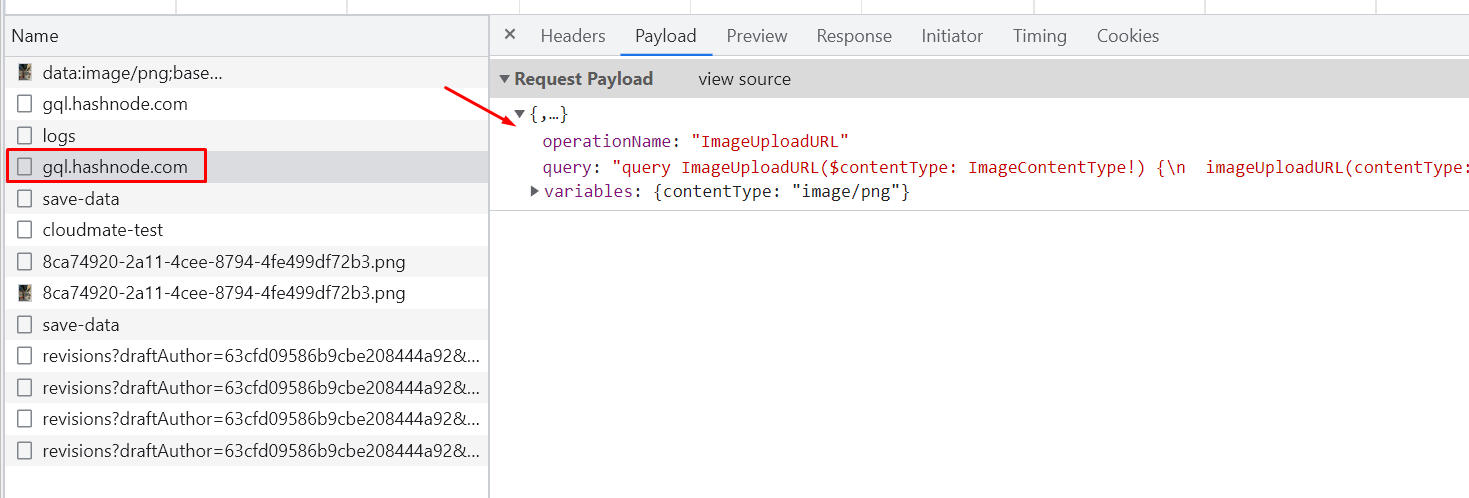
A POST request with graphql query to https://gql.hashnode.com/ which generates the URL of the image and provides credentials for us to upload the image to the Amazon S3 server. Request:
Response:
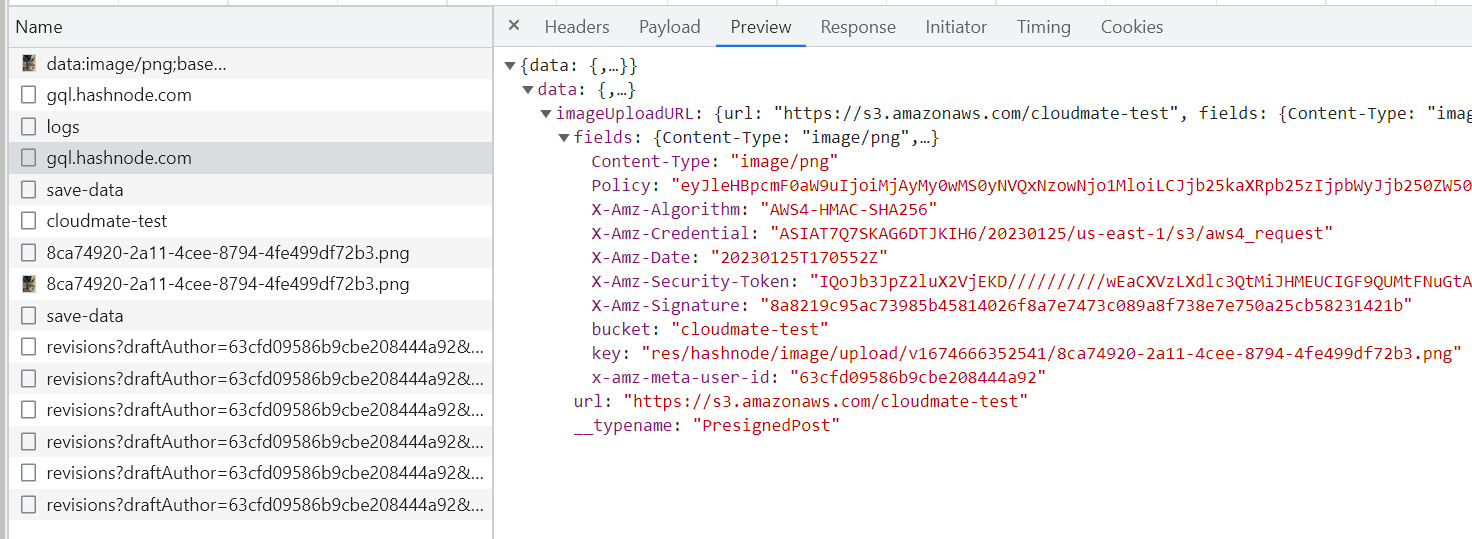
A POST request to https://s3.amazonaws.com/cloudmate-test which uses the credentials from the first request and send the image as binary data. You can see the form keys that correspond to the data of the first request's response.
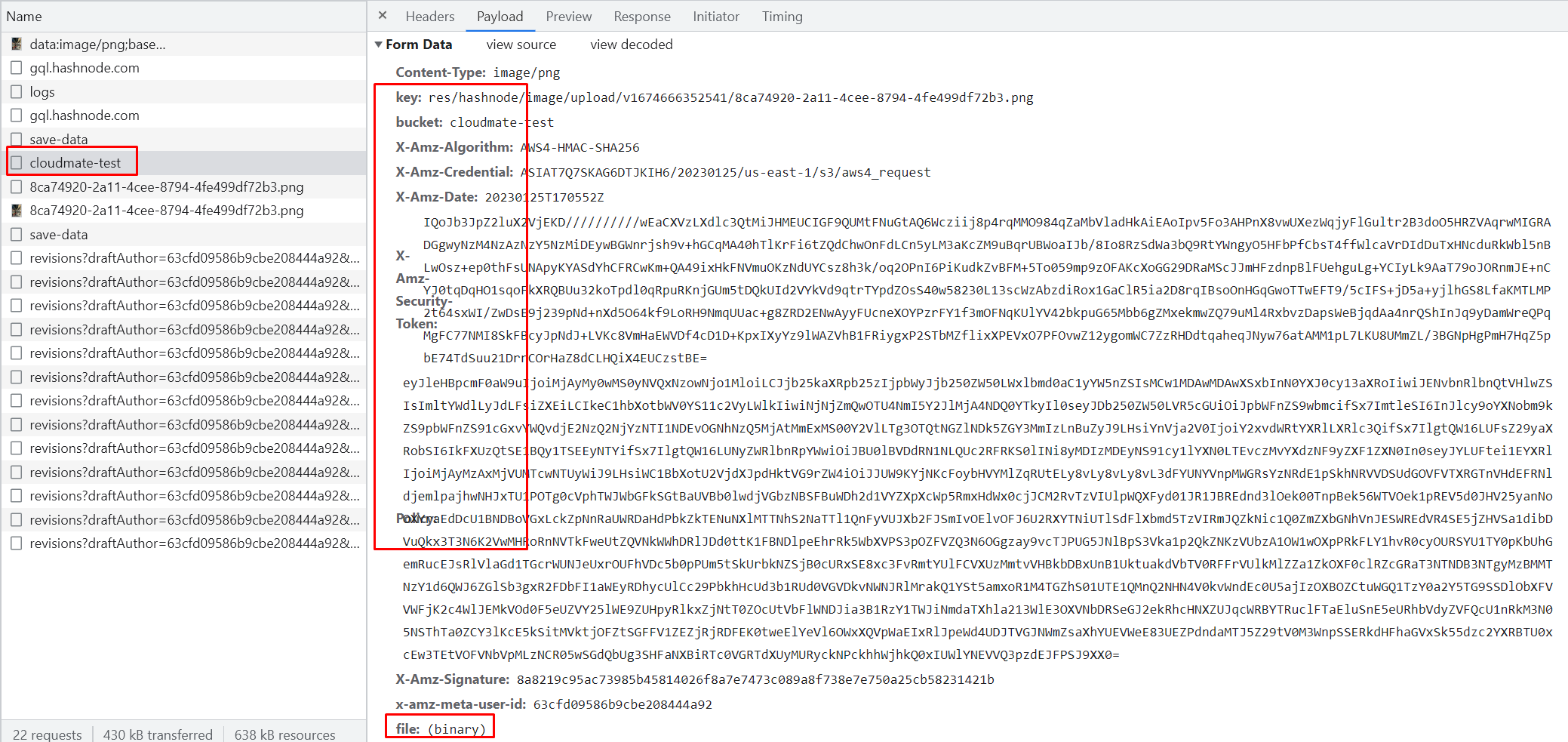
Now that I understand the requests' specifications, the next step is to implement them. I forked the repo above to https://github.com/t-rekttt/hashnode-sdk-js to add my new implementations.
Looked into the implementation inside base.ts I knew that the author has been using node-fetch it to implement his query.
Original API code using node-fetch
import fetch from "node-fetch";
const apiURL = "https://api.hashnode.com";
const apiKey = process.env.HASHNODE_API_KEY;
/**
* Hashnode API's returned errors.
*/
export class APIError extends Error {
readonly errors: any[];
constructor(errors: any[]) {
super(`Hashnode API error: ${JSON.stringify(errors, null, 2)}.`);
this.errors = errors;
}
}
/**
* Generic utility to make a Hashnode API's call.
*
* @param gql GraphQL query.
* @param variables Variables expression.
*/
export const query = (gql: string, variables: any) =>
fetch(apiURL, {
method: "POST",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
Authorization: apiKey || "",
},
body: JSON.stringify({
query: gql,
variables,
}),
})
// Parse JSON body.
.then(async (res) => ({ ok: res.ok, json: await res.json() }))
// Check for API errors.
.then((res) => {
if (!res.ok || res.json.errors) throw new APIError(res.json.errors);
return res.json;
});
Initially, I was going to follow his convention and continue using node-fetch to implement the image upload, but that decision made me suffer. Somehow the library was not calculating the Content-Length header automatically which made the server threw errors to my face complaining about me not telling the server about the image size. I tried to fix by calculating the header myself but it mismatched. Overall coping with node-fetch took me about 3-4 hours of desperation without getting anything solved or knowing why it mismatched (the size calculated in the header is much bigger than the image size in bytes).
After that, I decided to switch to a library that was deprecated but much more familiar to me, the request-promise . Suddenly I put the calls in and everything got to work. No more error was given.
Here are my implementations for the 2 requests described above:
Images migration requests implementation
export const queryUnofficial = async (
gql: string,
variables: any,
cookie: string
): Promise<any> => {
let res = await request(unofficalApiUrl, {
method: "POST",
headers: {
"Content-Type": "application/json",
Accept: "application/json",
Cookie: cookie,
},
body: {
query: gql,
variables,
},
json: true,
});
if (res?.errors) throw new APIError(res?.errors);
return res;
};
export const uploadImageToAmazon = async (fields: object, imageStream: any) => {
let res = await request.post(imageUploadApiUrl, {
formData: {
...fields,
file: {
value: imageStream,
options: {
filename: "image.png",
contentType: "image/png",
},
},
},
resolveWithFullResponse: true,
simple: false,
});
if (res.statusCode !== 204) throw new APIError([res.body]);
return res;
};
Ok, good. Now what I need to do in order to migrate a post with all its images is:
Loop through the image paths inside the post using the
post['mobiledoc']field.Get the md5 hash of the image and map it to the local path.
Upload (restore) the images to Hashnode's S3 server.
Replace the path of the images inside the post's HTML code.
Create the post
Images migration function
let migrateImages = async (post: any) => {
let postHtml = post.html;
let postId = post.uuid;
let mobileDoc = JSON.parse(post.mobiledoc);
let cards = mobileDoc.cards;
for (let card of cards) {
if (card[0] == "image") {
let retries = 0;
let newImageUrl: string | null = null;
let imagePath = card[1].src;
while (retries <= 3) {
try {
retries++;
if (!postHtml.includes(imagePath)) {
console.log(`Skipped ${imagePath}`);
break;
}
let hash = MD5(imagePath).toString();
let localImagePath = `./images/${postId}/${hash}.png`;
try {
await sharp(localImagePath)
.png({ quality: 80 })
.toFile("./images/tmp.png");
} catch (err) {
console.log(err);
break;
}
newImageUrl = await uploadImage(
fs.createReadStream("./images/tmp.png"),
HASHNODE_COOKIE || ""
);
break;
} catch (error) {
console.log(error);
}
}
if (!newImageUrl) {
console.log(`Given up on image ${imagePath}`);
continue;
}
console.log(`Uploaded image ${imagePath}, new url: ${newImageUrl}`);
postHtml = postHtml.replace(new RegExp(imagePath, "g"), newImageUrl);
}
}
return postHtml;
};
The code looks a bit nested because I added some try-catch with 3 retries in order to make sure my script will not fail because of any stupid HTTP timeout exception.
You might notice this small piece of code inside the function above also, it's for compressing the image to prevent the image from passing S3's image size limit (I think the limit is 5MB):
await sharp(localImagePath)
.png({ quality: 80 })
.toFile("./images/tmp.png");
And with the same demo post from above, here is how it looks on my new Hashnode blog:
Third challenge: Draft, tags, backdated time migration - For a tailored experience
Successfully migrated all the posts' content and images, it looks like I've satisfied my original needs in order to get rid of Ghost.
But look into the small details: now all my posts have almost the same published date, drafts were not migrated or turned into published posts (Hashnode has no option to unpublish posts yet), and tags were gone. There is no way anyone who is serious at blogging would consider a half-baked migration like that.
So in order to convince people that I'm seriously blogging 🤣, I decided to try to cover all of those.
It's easier said than done, out of my surprise, almost each of my purpose requires a different API implementation:
For backdating posts and migrating tags: Update post API.
For drafts migration with tags and backdated time: Create draft API, update draft API.
The method is identical. I used Chrome Devtools to capture the requests while tweaking some options, to see which leads to what.
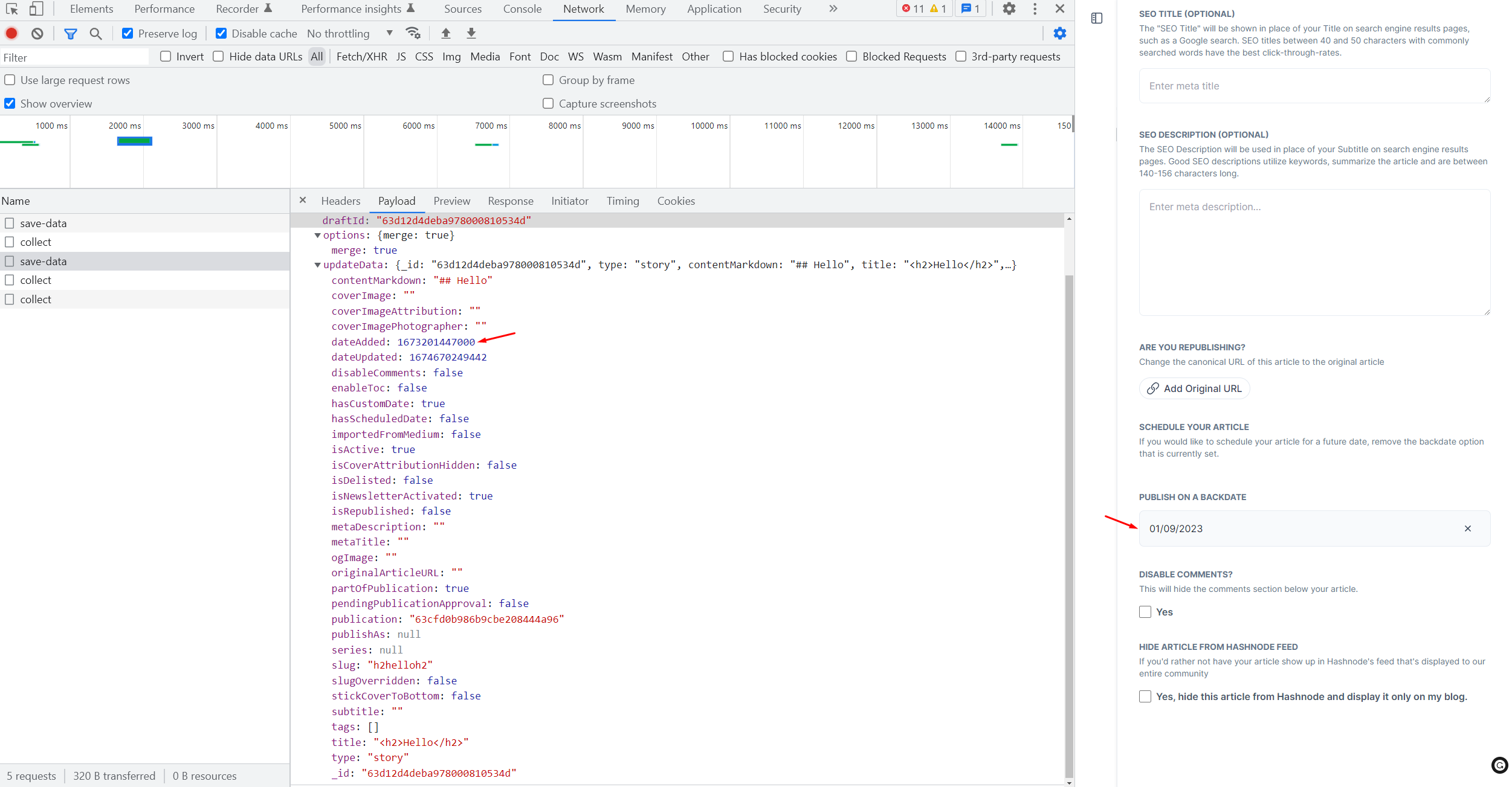
And so the examination turned into the implementation below:
HTTP requests implementations
// Update post
export const sendAjaxUpdatePost = (data : PostUpdate, cookie: string) => {
return request.post(`${ajaxApiUnofficial}/post/update`, {
body: data,
json: true,
headers: {
Cookie: cookie,
},
});
}
// Create & update drafts
export const createDraftUnofficial = async(publicationId : Publication["id"], cookie : string) => {
let res = await request.get("https://hashnode.com/draft", {
qs: {
new: true,
publicationId,
},
headers: {
Cookie: cookie,
},
json: true,
resolveWithFullResponse: true,
simple: false,
followRedirect: false
});
if (res.statusCode !== 307)
throw new APIError(res.body);
return res.headers['location'];
}
export const updateDraftUnofficial = (data : DraftUpdate, cookie : string) => {
return request.post("https://hashnode.com/api/draft/save-data", {
body: data,
json: true,
headers: {
Cookie: cookie
}
});
}
Migration functions for posts and drafts
let migratePublishedPost = async (
publicationId: string,
post: any,
tags: any
): Promise<boolean> => {
let postTitle = post.title;
let postSlug = post.slug;
let postCreationTime = post.created_at;
let postHtml = await migrateImages(post);
const article = await createPublicationArticle(
HASHNODE_API_KEY || "",
publicationId,
{
title: postTitle,
slug: postSlug,
contentMarkdown: postHtml,
}
);
console.log(`Created article ${postTitle}`);
await updatePublicationArticleUnofficial(
{
post: {
title: postTitle,
subtitle: "",
contentMarkdown: postHtml,
tags: tags.map((tag: string) => ({
name: tag,
slug: tag,
_id: null,
logo: null,
})),
pollOptions: [],
type: "story",
coverImage: "",
coverImageAttribution: "",
coverImagePhotographer: "",
isCoverAttributionHidden: false,
ogImage: "",
metaTitle: "",
metaDescription: "",
isRepublished: false,
originalArticleURL: "",
partOfPublication: true,
publication: publicationId,
slug: postSlug,
slugOverridden: false,
importedFromMedium: false,
dateAdded: new Date(postCreationTime).getTime(),
hasCustomDate: true,
hasScheduledDate: false,
isDelisted: false,
disableComments: false,
stickCoverToBottom: false,
enableToc: true,
isNewsletterActivated: true,
_id: article.id,
hasLatex: false,
},
draftId: true,
},
HASHNODE_COOKIE || ""
);
console.log(`Updated article ${postTitle}`);
return true;
};
let migrateDraft = async (
user: User,
post: any,
tags: any,
publicationId: Publication["id"] = user.publication.id
) => {
let postTitle = post.title;
let postSlug = post.slug;
let postCreationTime = post.created_at;
let draftId = await createDraftUnofficial(
publicationId,
HASHNODE_COOKIE || ""
);
console.log(`Created draft ${draftId}`);
let postHtml = await migrateImages(post);
let data = {
updateData: {
_id: draftId,
type: "story",
contentMarkdown: postHtml,
title: postTitle,
subtitle: "",
slug: postSlug,
slugOverridden: false,
tags: tags.map((tag: string) => ({
name: tag,
slug: tag,
_id: null,
logo: null,
})),
coverImage: "",
coverImageAttribution: "",
coverImagePhotographer: "",
isCoverAttributionHidden: false,
ogImage: "",
metaTitle: "",
metaDescription: "",
originalArticleURL: "",
isRepublished: false,
partOfPublication: true,
publication: publicationId,
isDelisted: false,
dateAdded: "",
importedFromMedium: false,
dateUpdated: postCreationTime,
hasCustomDate: false,
hasScheduledDate: false,
isActive: true,
series: null,
pendingPublicationApproval: false,
disableComments: false,
stickCoverToBottom: false,
enableToc: false,
publishAs: null,
isNewsletterActivated: true,
},
draftAuthor: user.id,
draftId: draftId,
options: {
merge: true,
},
};
let result = await updateDraftUnofficial(data, HASHNODE_COOKIE || "");
if (result) console.log(`Updated draft ${draftId}`);
else console.log(`Update draft ${draftId} failed`);
return result;
};
Tags mapping
let getTags = (post: any, postsTags: any, tags: any) => {
let postId = post.id;
let filteredPostTags = postsTags
.filter((item: any) => item.post_id == postId)
.map((item: any) => item.tag_id);
let filteredTags = tags
.filter((tag: any) => filteredPostTags.includes(tag.id))
.map((item: any) => item.name);
return filteredTags;
};
Source codes
Hashnode API implementation
Ghost migration scripts
Afterword
If you reached this part of the post, I want to say thank you for reading, your attention is considered big support for me. Hope it would help if you are consider moving from Ghost.
If you like my post, please consider giving a star 🌟.
As I'm just started to code using typescript, my code looks crap. Please feel free to open PRs if you are willing to help 🤩.
Sharing the post would be much appreciated (especially since I'm trying to surpass my friend 🤣).
Credits
- hashnode-sdk-js by phuctm97
- Thumbnail icons resources by pikisuperstar